Sensing technologies are producing unprecedented amounts of data about the environment and the digital world. The current question is: how can we gain true insight from all the available measurements? Industries are orienting development towards new systems built around higher requirements of performance and scale. Effective storage is an important precondition for big data analytics, but insight is ultimately related to the nature of collected data and where it originated.
Sensing technologies are producing unprecedented amounts of data about the environment and the digital world. The current question is: how can we gain true insight from all the available measurements? Industries are orienting development towards new systems built around higher requirements of performance and scale. Effective storage is an important precondition for big data analytics, but insight is ultimately related to the nature of collected data and where it originated.
Our view about collecting data has changed in recent times. From a controlled and organized exposure to the world by means of scientific analysis, data have become the result of a new generalized attitude for measurement. The nature of data has become increasingly less structured and free-form, consisting mostly of Twitter or Facebook text feeds, photo and video uploads with scarce or non-existent metadata, web content or transactions stored in disparate servers, the stream of individual sensors about specific environments, and so on. Such data are entirely different from the structured data used by most GIS databases where tabular representations, linked data organizations of records or even specific ontologies deliver rich information. Rather, automation in data analysis seems to require the opposite approach.
Systems must be able to reconstruct the overall information insight from scarce clues by means of great amounts of computation, directed by clever algorithms. Is that strategy feasible? The following news indicate how the industry is making great strides to make computation evolve to accommodate the changing quality and quantity of data. But advancements in computation might not be enough.
Reduction in computer power consumption and increased performance within the envelope of steady technological innovation have allowed many players to have a “head-on” computational approach to the quest for insight. Nvidia is a graphical chip maker that offers hardware and research support for the industries solving problems using enhanced computational performance. In occasion of the recent developers’ conference the company underlined its current orientation to store, organize and compute big data with the help of general-purpose graphical processing units (GPGPUs). Such hardware is a better performing alternative to traditional processors in carrying out data intensive tasks, including GEOINT (mainly geointelligence and defense-oriented) applications.
Nvidia’s market is mostly in consumer computing, providing enthusiasts with graphical hardware for computer games, whose ever-increasing performance requirements actively drive the industry forward. The high-performance niche offers an anticipation of several years over things to come in the mainstream. Real-time big data databases like Map-D are able to exploit greater hardware memory efficiencies to offer real-time information visualization over massive Twitter geocoded text datasets (see Figure 1).
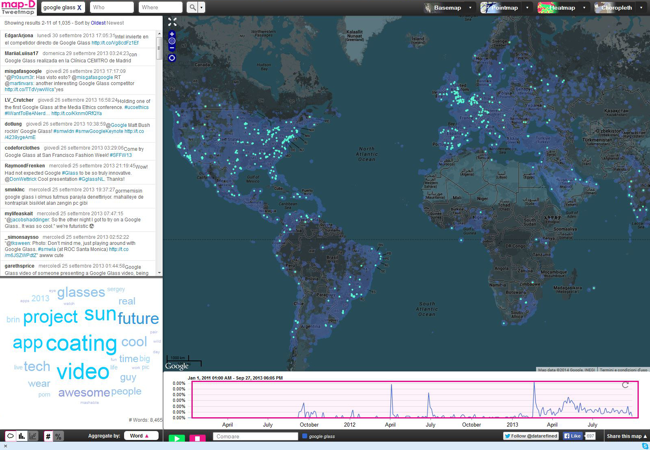 Figure 1 – This Map-D interface provides visualization of a query of Twitter feeds concerning Google Glass using several tools.
Figure 1 – This Map-D interface provides visualization of a query of Twitter feeds concerning Google Glass using several tools.
Also in software, new approaches in database technologies are moving beyond traditional relational database management system (RDBMS), mainly to address new issues of data volume and readiness of access. For example, in recent times Google introduced Spanner, a new generation database designed to provide a global geographic infrastructure able to respond to the company’s web services’ requests. It is based upon a simpler data model and is able to attain higher performance and reliability by using a distributed and redundant architecture.
Similarly, the open source project Hadoop has become a much renowned platform for efficiently storing and analyzing very large data collections. It employs new methods of data storage that break with the tradition and introduce a more performing data management. Large amounts of data are subdivided in chunks at multiple storage locations and are easily handled by means of local processing without incurring in the performance limitations of traditional centralized servers.
As a result of the specific computational focus of the entire industry, automation and unsupervised information extraction and data mining strategies are preferred, with artificial intelligence and machine learning tackling the task of making sense of the collected data. Alternatively, humans would be requested to control complex, partially automated databases to deliver the last and most critical mile of understanding to the problem at hand. In both cases, the original data would be given an interpretation according to a specific task or application. For example, public sentiment or consumer orientation on social networks could be spotted by a human observer with an exploratory visualization or result entirely from machine learning on data taken directly from a computer.
At this point, a question seems more important than discussing any further implementation: what is the linkage between insight and effectively stored data? The strategy of hoarding data to make later critical leaps in understanding might wrongly privilege quantity over quality, and deprive the process of information-seeking of much structure and meaning. It seems that current technologies, initially aimed at sensing, would really try to perceive: not only to record and store for a later smart use, but rather to find the structure apparently lost in the way data are immediately available. The examples that follows will try to indicate how knowledge of human behavior and geographic information may be helpful in giving the required order to data.
An example may be provided by a human explorer walking in a natural landscape. Imagine that while freely walking, she is recording the ongoing exploration down to the details of the motion of her eyes (for example, using a next-gen Google Glass app). In theory, it would be possible to collect a complete set of data about her viewing experience, and have a precise idea about where she has looked. We could for example cross-check the data with a digital model of the environment to understand what she has seen.
However, it is very hard to extract from such a continuous log the precise spatial information that she acquires about the surrounding landscape. In fact, the analyst would end up with an enormous amount of unstructured data that contemplates every turn of the head and every subtle change of the terrain profile on which she is walking, in addition to the erratic motion of the eyes. A more meaningful approach would be to see the data as being a sum of multiple layers of motion, informed by previous knowledge about the usual process of exploration and not only from the data stream.
In the same way, the analysis of unstructured data should start from knowledge of the spatial structure of the real world and human behavior, an advantageous start with respect to a geography-agnostic image-based model alone. In other words, unstructured data has in reality much structure related to the nature of the observer and the spatial context of observation, and that is true in the case of photos, videos, descriptions, etc.
In another example we want to obtain globally-referenced information from an unstructured data stream, for example to build a Digital Earth database. A big data element would be similar to a fragment of a single view from a specific location, a single transaction between two locations, or the part of a service grid activated by a person. Geographical information is the embedded strategic clue that is able to link every element to the overarching geographic architecture. Therefore, clues in the data can be ranked according to how much global structure they contain. The quest for insight would become the strategic task of acquiring clues from data, rank them according to their information content and make use of the embedded information as a reference. In this case, quantity of information is a prerequisite for the strategic search but the task should be attuned with the specific quality of spatial information and its architecture.
The architecture is normally given by global latitude-longitude reference systems, down to relative expressions of proximity and distance. For an unstructured data stream, the same could be true: spatial structure intrudes into any outdoor or indoor video, sensor network, geocoded Twitter feed, etc.. The “where” is not only the place-of-origin information presented in common metadata, but any spatial information that can be found, such as a floor plan, networking scheme, textual reference to spatial behavior, and so on. Those are more complex clues to perform geolocation than basic coordinates. They would carry out a role corresponding to the Semantic Web in the different but parallel task of making sense of web data.
Unstructured big data seems to need a new reference “datum”. The datum would not only be related to an expression of analytical coordinates, as the one used in mapping to place coordinates in a global reference frame. Instead, it should also be rich of our knowledge of human behavior as an underlying ordering rule for any data being produced within a geographic environment or containing information about it.